
Meet DailyTalk: The Latest Conversational Text-to-Speech Dataset based on FastSpeech Framework
The global Conversational Text-to-Speech market is witnessing a rapid rise. In the last 3-4 years, we have covered the various facets of this dynamic Machine Learning capability that allows users to deliver highly contextual and personalized experiences. Conversational Text-to-Speech capabilities (TTS) are widely used to create human voices to interact, train and engage with real humans. Adding to the family of TTS datasets, AI researchers associated with the School of Computing at KAIST in Korea have introduced “DailyTalk.” DailyTalk is a highly advanced conversational ML-based conversational TTS dataset specifically designed for conversational systems.
Here’s a quick overview of the DailyTalk conversational TTS dataset and its foreseeable application in the near future in conversational systems.
What is DailyTalk?
DailyTalk is a part of the next-gen TTS datasets developed using the open source dialogue dataset DailyDialog. The AI researchers credited for building the DailyTalk used FastSpeech framework as the baseline, recording and modifying over 2500 different dialogues from DailyDialog. The resultant TTS dataset has been put to use to train advanced NLPs and TTS conversational systems and available for academic review as part of CC-BY-SA 4.0 license.
Why the Korean AI Researchers Developed TTS Dataset like DailyTalk?
AI companies are in the race to build the most sophisticated set of human voices that covers for a wide range of human-sounding conversations. Advanced Neural TTS models look to imbibe additional human component such as emotions, tones, and pauses to create unique machine-based voice personas. These could be used in different applications such as call center conversations, voice-based chats, virtual assistants and so on.
AI researchers Keon Lee, Kyumin Park and Daeyoung Kim identified the limitations of using conventional TTS models. These limitations were related to context representations which overlooked the importance of dialogue, background noises and record-quality, which influence the quality of conversation in real-world scenarios. DailyTalk’s high quality dialogue speech dataset for TTS systems analyses both general as well as conversational speech synethsis quality, rendering world’s first open dataset for conversational TTS.
Popular Neural TTS Models that Researches Analysed before Introducing DailyTalk
DailyTalk creators analyzed the pros and cons and the TTS deliverables of various models. These models are:
- LJSpeech
- LibriTS
- VCTK
- Blizzard Challenge
- AdaSpeech3
DailyTalk, by introducing TTS model as an open dataset strives to remove the blockade to developing the most advanced high-quality conversational text-to-speech or speech synthesis models.
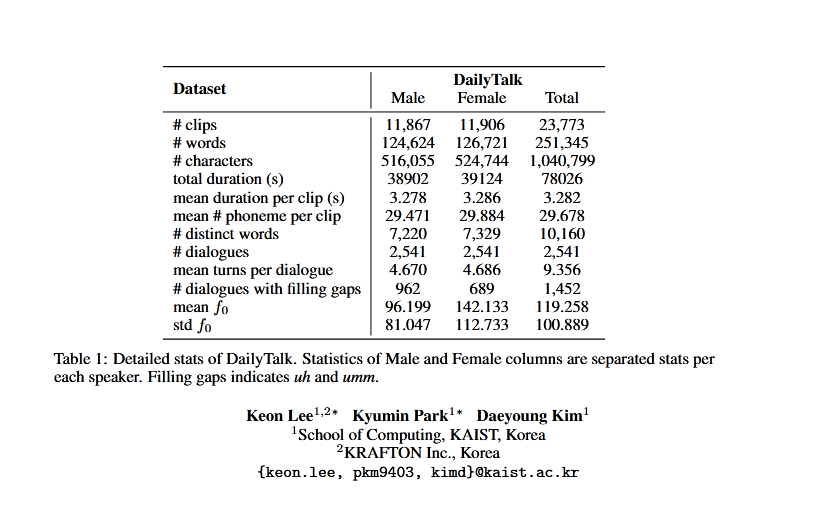
The researchers have published the detailed stats of DailyTalk and the speech processing pipeline at various stages of recording and processing. The analysis consisted of 23773 audio clips with a run-time of around 20 hours.
Conversational Text-to-Speech
Use of FastSpeech as Backbone of TTS Baseline
The aim of the DailyTalk development team was always clear from the beginning—to build a TTS model that represents the differences between various context-related dialogue characteristics. The existing frameworks such as Tacotron2 couldn’t meet the expectations due to the difficulty in aligning with the training data. FastSpeech series provided the apt environment to maintain robust speech synthesis. Now, to make FastSpeech work in TTS models favour, AI researchers used the Backbone TTS FastSpeech framework with context encoder. The team used NVIDIA RTX 3090 in the experiments.
DailyTalk Dataset and AI Ethics
The dataset doesn’t contain any PII, and the transcripts used in this experiment are derived from the DailyDialog dataset. Though acting voice and gender information have been mentioned in the dataset, these are broad-range and the actors have agreed to allow distribution of these information in recording as a dataset.
This research was supported by the MSIT(Ministry of Science and ICT), Korea, under the Grand Information Technology Research Center support program(IITP-2022-2020-0-01489) supervised by the IITP(Institute for Information & communications Technology Planning & Evaluation).
View the paper and images here
Comments are closed.