
Regardless of the different types of definitions present on the world wide web, Artificial Intelligence, in essence, is always about mimicking the abilities of a human mind. Among these abilities, language is a fundamental capability of humans to communicate with each other. It is the same reason that the big corporations are working day and night to advance AI in the language in the form of Natural Language Processing or NLP. This field comes as an intersection of computer science, AI, and linguistic. The ultimate goal here is to make computers understand natural language to perform all our textual digital tasks.
NLP has become a significant part of the information age, which in turn, is a crucial part of AI. It has given and made our life quite simple in the form of digital virtual assistants, voice interfaces, chatbots, and much more. Some other NLP instances include Spell Checking, Keyword Search, Finding Synonyms, Information Extraction, Sentiment Analysis, Machine Translation, dialog systems, and complex question answering. Furthermore, more and more applications are developed every day in the advancement of NLP.
Hence, in this article, we will go through the different types of NLP techniques. And before we do that, let’s quickly go over what NLP actually is.
NLP Definition
A leader in analytics, SAS describes NLP as “Natural language processing (NLP) is a branch of artificial intelligence that helps computers understand, interpret and manipulate human language. NLP draws from many disciplines, including computer science and computational linguistics, in its pursuit to fill the gap between human communication and computer understanding.”
Hence, we can say that NLP is the automated manipulation of natural language such as speech or text by software. The study of natural language processing has been around for more than 50 years and grew out of the field of linguistics with the rise of computers.
In NLP, the structure and meaning of human speech are used to analyze various aspects such as syntax, semantics, pragmatics, and morphology. Computer science then converts this language knowledge, which can solve certain problems and perform desired tasks, into rules-based, machine learning algorithms. This is how Gmail is able to segregate our email tabs, software correct our textual grammar, voice assistants can understand us, and the systems can filter or categorize their content.
Now that we have covered the definition and working methodologies, let’s transition to NLP techniques.
Named Entity Recognition
Named Entity Recognition (NER) is the first step towards information extraction that aims to segregate ‘named entities’ into pre-defined categories. These categories can range from the name of the person to locations, organization, expressions of time, percentages, monetary values, etc. NER in NLP answers the ‘what’ and ‘why’ aspects of the world problems. Instances of such can include what person or business’ names were mentioned in the article, name/information about the product, location of any useful entity.

- Entity Categorization — This algorithm searches all news articles automatically and extracts information from the post, such as persons, businesses, organizations, people, celebrities, locations. This algorithm helps us to sort news content conveniently into various categories.
- Search Engine — All articles, data, news that is to be extracted and stored separately refer to the NER algorithm. This increases the search process and makes up for an efficient search engine.
- Customer Support — Businesses receive massive amounts of feedbacks and reviews on a daily basis forming a new set of colossal data. Herein, NER API can easily pick out all the relevant tags to help businesses make sense of this data.
Tokenization
Tokenization is one of the most common activities in dealing with text information. Tokenization is the division of a given text into a list of tokens. These lists contain anything like sentences, phrases, characters, numbers, punctuation, and more. There are two significant advantages to the process. One is to reduce discovery time to a large degree, and the latter is to be successful in the usage of storage space. The method of mapping sentences from characters to strings and strings to words is initially the basic stage of any NLP problem since, in order to comprehend any text or document, we need to understand the context of the text by reading the words/sentences present in the text.

Tokenization is an essential part of every Information Retrieval (IR) framework, not only includes the pre-processing of text but also creates tokens that are used in the indexing/ranking process. Various techniques of tokenization are available, among which the Porter Algorithm is one of the most popular techniques.
Sentiment Analysis
Sentiment Analysis informs us whether our data is correlated with an optimistic or pessimistic outlook. Although there are various techniques of producing sentiment analysis, typical use cases include defining the emotion conveyed in a statement or collection of sentences in order to achieve a general interpretation of the customers’ mood. In marketing, this can be helpful in understanding how people respond to various types of communication.
Sentiment analysis can be conducted using both supervised and unsupervised methods. Naive Bayes is the most common supervised model used for sentiment analysis. Besides Naive Bayes, other machine learning methods like the random forest or gradient boosting can also be used. Unsupervised approaches, also known as lexicon-based strategies involve a corpus of words with their related feeling and polarity. The sentence’s sentiment score is determined using the phrase’s polarity.
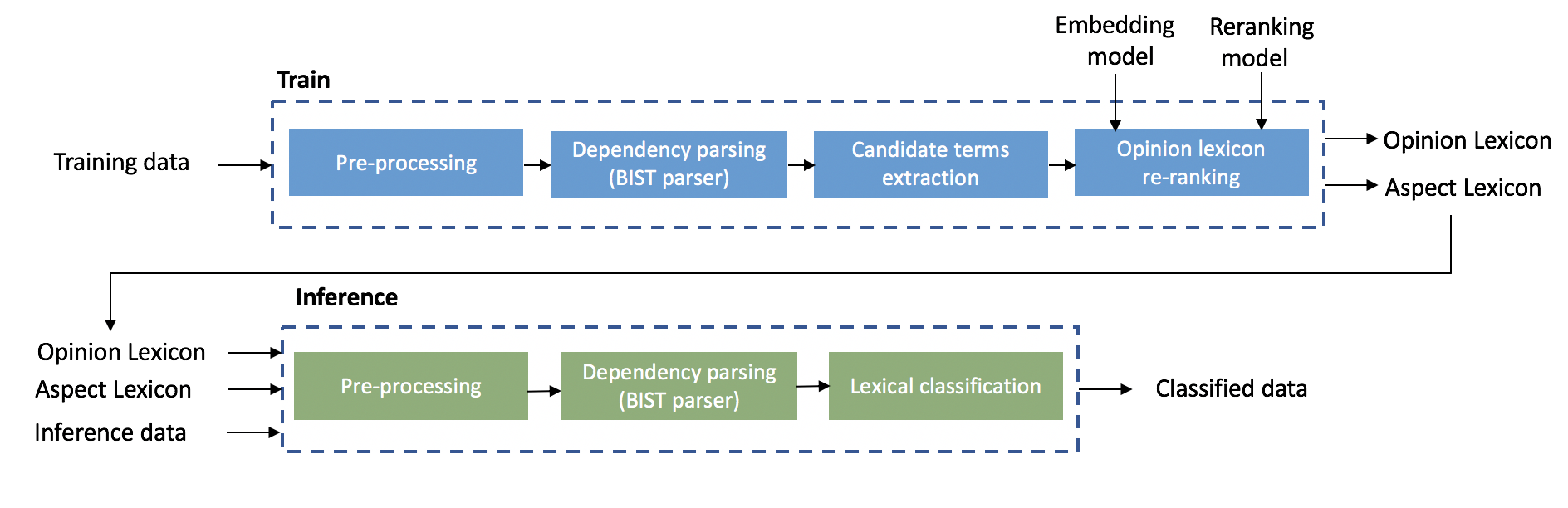
The Intel AI Lab has developed a lightly-supervised ABSA solution that was released as part of the NLP Architect open-source library version 0.4 in April 2019. This solution enables a wide variety of users to generate a detailed sentiment report. The solution flow is divided into two phases, training and inference.
Automatic Text Summarization
Automatic Text Summary is a method of producing a succinct and accurate text summary from various text tools. These tools can vary from books, news stories, blog posts, academic papers, emails, and tweets. The demand for automated text summarization systems is increasing these days due to the availability of vast volumes of textual data.

Text summarization can be narrowly separated into two categories—Extractive Summarization and Abstract Summarization.
- Extractive Summarization — These approaches rely on separating a variety of pieces, such as sentences and phrases, from a piece of text and stacking them together to create a description. The identification of the relevant sentences for summarization is thus of the utmost importance in the extractive system.
- Abstractive Summarization — These approaches use sophisticated NLP techniques to produce a brand new description. Any portions of this summary may not appear in the original text.
Keyword Detection for SEO Techniques
The keyword detection is used by creating a short line list of common words in your text data and comparing it to the current SEO keyword list to build or allow search engine optimization (SEO) techniques. Herein, businesses will scan the data to find the most relevant keywords, also distinctive substantive. From here, they will draw up a list of words, one shortlist based on features and the other on price, which correlates more closely to the questions of each product. They will also create a (new) SEO keyword list to help boost your click rate and eventually gain more traffic.
For example, a business could examine email support from its customers and point out that one of the items has more concerns about features than price.
Topic Modelling
Topic Modelling technique is applied to break down a large amount of text body into relevant keywords and ideas. Afterward, you can extract the main topic of the text body. This advanced technique is built upon unsupervised machine learning that does not depend on data for training. Correlated Topic Model, Latent Dirichlet Allocation, and Latent Sentiment Analysis are some of the algorithms that can be utilized to model a text body topic. Among these, Latent Dirichlet is the most popular which examines the text body, isolates words and phrases, and then extracts different topics. A text body is only required for the algorithm to work.

Indium’s teX.ai, a SaaS-based accelerator is an example that identifies the latent topic inside documents without reading them using Topic Modeling.
Natural language processing is a branch of artificial intelligence and computational linguistics. The main objective of NLP is to take the human spoken or written language, process it, and convert it into a machine-understandable form. In other words, we are trying to extract the meaning from natural language, be it English or any other language.
Businesses can use NLP in numerous areas from medical informatics to marketing and advertising. NLP is definitely applicable for analyzing the content of huge datasets. There are various techniques used in NLP such as Sentiment Analysis, Named Entity Recognition, Text Mining, Information Extraction, and so on. Once these techniques are applied, information can be collected and fed into machine learning algorithms to produce accurate and relevant use.