
Meet StabilityAI’s DeepFloyd IF – The Text-to-Image Model Comes With Sophisticated Integration Capabilities
DeepFloyd IF, a potent text-to-image cascaded pixel diffusion model, was released for research use by Stability AI and its multimodal AI research center DeepFloyd.
DeepFloyd IF is a cutting-edge text-to-image model that was made available under a non-commercial, research-permissible license, giving researchers the chance to study and test out advanced text-to-image creation techniques.
In the future, Stability AI plans to make the DeepFloyd IF model completely open source much like other Stability AI models.
DeepFloyd IF – Features
- Prompt understanding: Large language model T5-XXL-1.1 is used as the text encoder for the generating pipeline. Better prompt and picture alliance is also provided by a substantial amount of text-image cross-attention layers.
- Text description into images: DeepFloyd IF creates cohesive and understandable language coupled with objects with diverse qualities emerging in various spatial relations through integrating the intelligence of the T5 model. The majority of text-to-image models have previously found it difficult to handle these use situations.
Recommended: Skilldora and D-ID in World First Accreditation for AI-Based eLearning
- Enhanced photorealism: The remarkable zero-shot FID score of 6.66 on the COCO dataset, which is the main measure used to assess the performance of text-to-image models and the lower the score, the better, reflects this quality.
- Aspect ratio shift: The capacity to produce images with non-square, non-square aspect ratios in addition to the square aspect.
- The original image is reduced in size to 64 pixels, noise is added using forward diffusion, and the image is then denoised using backward diffusion and a new prompt. Through super-resolution modules and a prompt text description, the style can be altered even further. This method enables to alter the output’s style, patterns, and details while still preserving the source image’s basic shape, all without any fine-tuning
![]() DeepFloyd IF – Definitions
DeepFloyd IF – Definitions
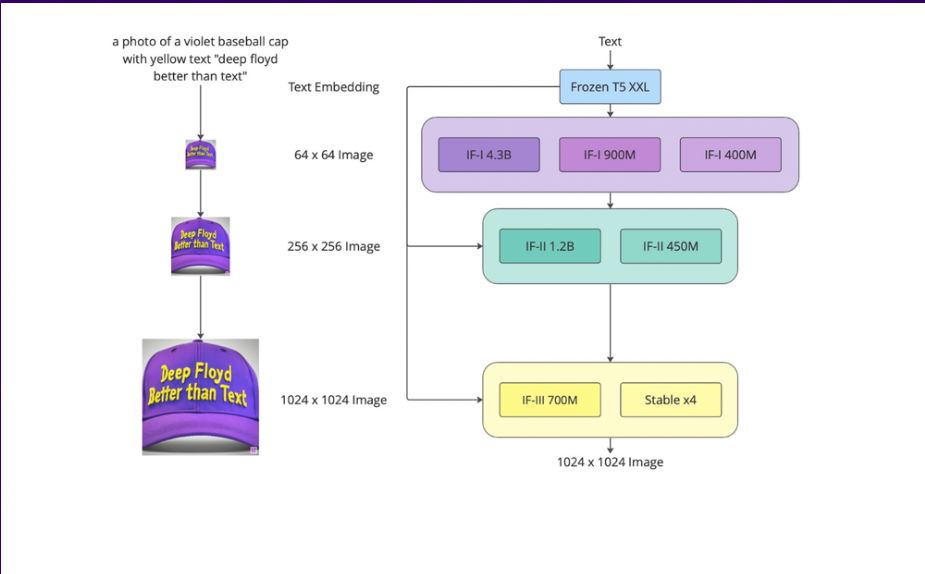 DeepFloyd IF – Definitions
DeepFloyd IF – DefinitionsDeepFloyd IF is a modular, cascaded, pixel diffusion model. Here, modular refers to several neural modules that DeepFloyd IF consists of. These neural networks are capable of independently solving tasks like upscaling and creating graphics from text prompts.
Using a sequence of independently trained models at various resolutions, DeepFloyd IF cascades models to model high-resolution data. The base and super-resolution models of DeepFloyd IF are diffusion models, where random noise is introduced into the data through the use of a Markov chain of steps before the method is reversed to create fresh data samples from the noise.
DeepFloyd IF – Dataset Training
A unique, high-quality LAION-A dataset with 1B (image, text) pairs was used to train DeepFloyd IF. After deduplication based on similarity hashing, additional cleaning, and other adjustments to the original dataset, LAION-A was created. It is an aesthetic subset of the English portion of the LAION-5B dataset. Watermarked, NSFW and other offensive content were removed using DeepFloyd’s proprietary filters.
Recommended: Hybrid Work Lifts Microsoft Cloud Use in Australia
DeepFloyd IF – Licence
The model’s designers seek suggestions to enhance the model’s functionality and scalability. It is first made available under a research license. The approach can be applied to a variety of fields, including accessibility, art, design, and narrative.
The publication of this model is consistent with Stability AI’s dedication to disseminating cutting-edge technologies to the larger research community.
[To share your insights with us, please write to sghosh@martechseries.com].



Comments are closed.