
AI HyperComputer + Cloud TPU v5p : A Robust Adaptable AI Accelerator
Google Unveiled a Performance-Tweaked Version of Its Tensor Processing Unit (TPU)
A revolutionary supercomputer architecture, the AI Hypercomputer from Google Cloud uses an integrated system of performance-optimized hardware, open software, leading ML frameworks, and flexible consumption models. It is also part of their announcement of other new products. Piecemeal, component-level improvements are a common way for traditional approaches to handle heavy AI workloads, but they can cause inefficiencies and bottlenecks. Hypercomputer AI, on the other hand, uses systems-level codesign to increase productivity and efficiency in AI training, tuning, and serving.
Emerging at a dizzying rate, generative AI (gen AI) models provide capabilities and sophistication that have never been seen before. This innovation gives businesses and programmers the tools they need to tackle difficult challenges and seize new opportunities in a wide range of sectors.
Significant Leap in AI Acceleration
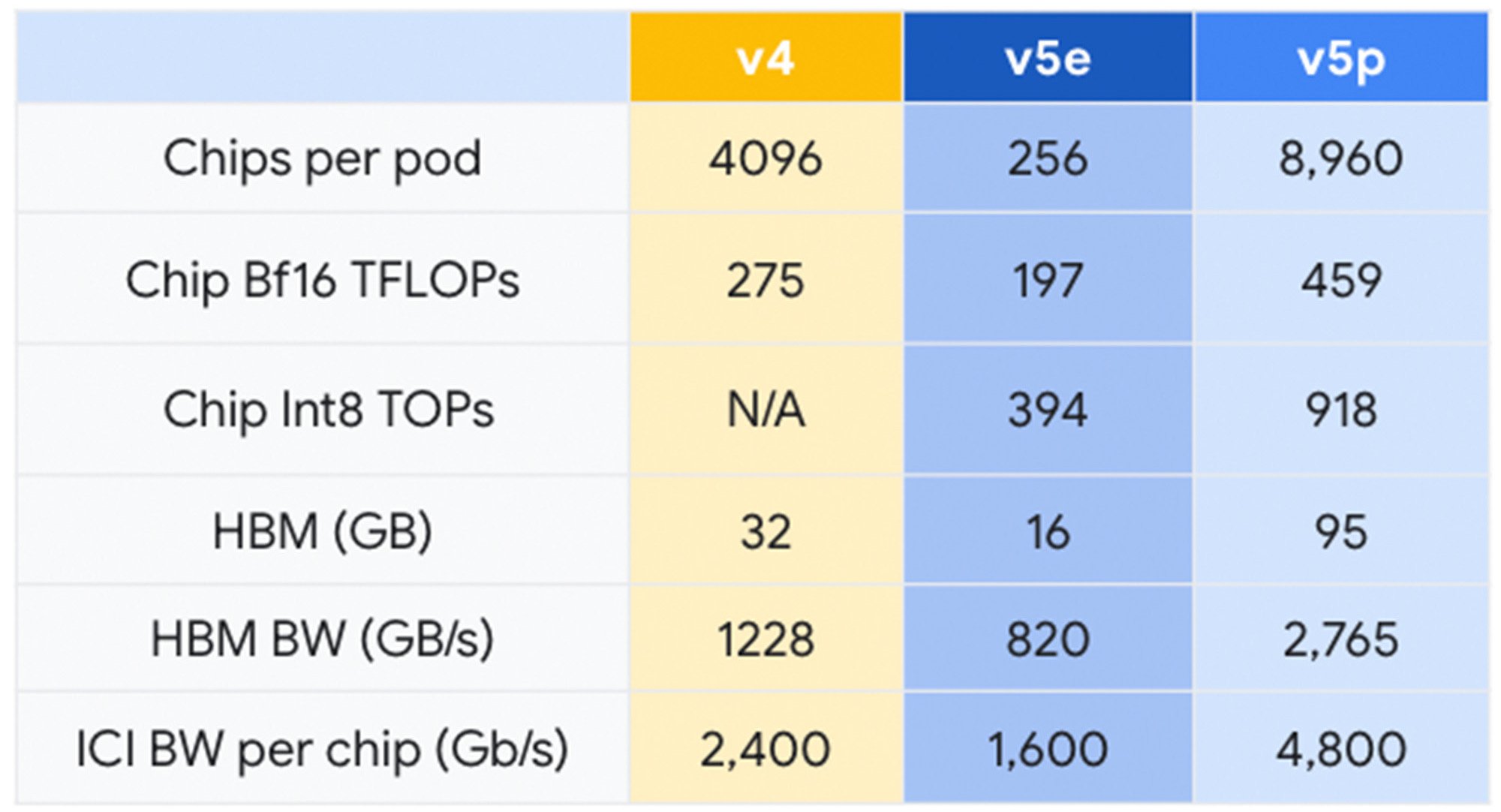
- Cloud TPU v5e was made generally available earlier this year. This TPU is our most cost-effective offering to date, with 2.3X price performance gains compared to TPU v41, our previous version. In contrast, our most powerful TPU up to this point is Cloud TPU v5p.
- In a 3D torus architecture, each TPU v5p pod consists of 8,960 chips connected by our highest-bandwidth inter-chip connection (ICI) at 4,800 Gbps/chip. The FLOPS and high-bandwidth memory (HBM) of TPU v5p is almost two and three times higher, respectively, than those of TPU v4.
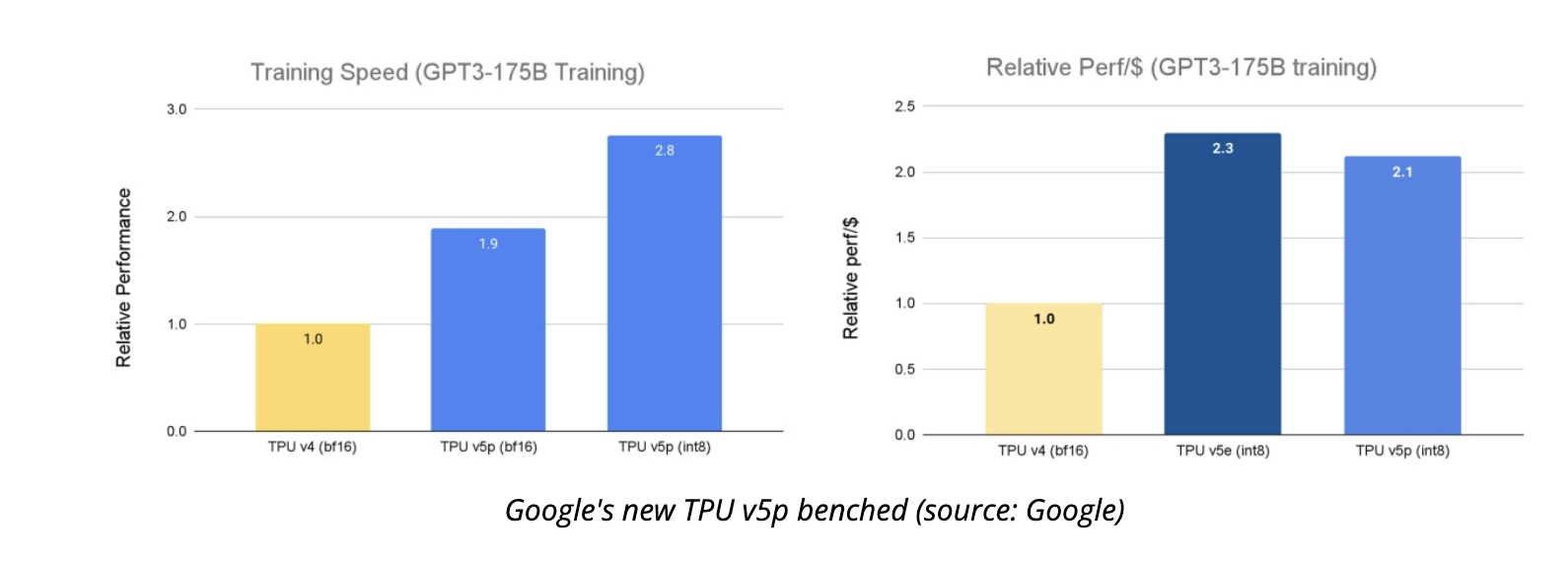
- With its enhanced speed, scalability, and flexibility, TPU v5p outperforms its predecessor, TPU v4, in training large LLM models by a factor of 2.8. In addition, TPU v5p can train embedding-dense models 1.9 times quicker than TPU v42 with second-generation SparseCores.
- Along with enhanced speed, TPU v5p offers four times the scalability of TPU v4 when it comes to the total number of FLOPs per pod. A significant gain in training speed is achieved by increasing the number of chips in a single pod and the floating-point operations per second (FLOPS) compared to TPU v4.
Google AI Hypercomputer Delivers Peak Performance and Efficiency at a Large Scale
To satisfy the demands of current AI/ML applications and services, it is essential to achieve both speed and scalability, yet these alone will not be enough. The computer system’s hardware and software parts must work in tandem to provide a dependable, secure, user-friendly, and integrated whole. At Google, engineers have spent decades perfecting this issue, and now they have AI Hypercomputer, a suite of technologies designed to collaborate seamlessly to power today’s AI workloads.

- An ultra-scale data center architecture, a high-density footprint, liquid cooling, and our Jupiter data center network technology are the building blocks of AI Hypercomputer’s performance-optimized computation, storage, and networking.
- Open software: AI Hypercomputer utilizes open software to provide developers access to our AI hardware that is optimized for performance. This software can be used to tune, manage, and dynamically coordinate AI training and inference workloads. They offer efficient resource management, uniform operations environments, autoscaling, auto-provisioning of node pools, auto-checkpointing, auto-resumption, and quick failure recovery through our deep interaction with Google Kubernetes Engine (GKE) and Google Compute Engine. For large-scale AI speech, AssemblyAI uses JAX/XLA and Cloud TPUs, and it optimizes distributed topologies across several hardware platforms to make model building straightforward and efficient for many AI use cases.
- Numerous adaptable and ever-changing consumption options are available with AI Hypercomputer. Not only does AI Hypercomputer provide traditional choices like Committed Use Discounts (CUD), on-demand pricing, and spot pricing, but its Dynamic Workload Scheduler also offers consumption models that are specifically designed for AI workloads. Calendar mode targets workloads with more predictability on job-start times, and Flex Start mode targets workloads with higher resource obtainability and optimal economics. Both models are introduced by Dynamic Workload Scheduler.
Leveraging Google’s Deep Experience to Help Power the Future of AI
Google Cloud’s TPU v5p AI Hypercomputer is already making an impact on customers like Salesforce and Lightricks, which are training and servicing big AI models: Over the years, we at Google have had faith in AI’s ability to assist in resolving complex issues. Training and serving major foundation models at scale has been a complex and costly ordeal for many organizations until recently. With the release of Cloud TPU v5p and AI Hypercomputer, we are thrilled to share the fruits of our customers’ labor in artificial intelligence and systems design, allowing them to develop with AI in a more streamlined, efficient, and cost-effective manner.
Read: How should CFOs approach generative AI
[To share your insights with us, please write to sghosh@martechseries.com]
Comments are closed.