
How Is NVIDIA Building AI Chatbots Using RAG?
NVIDIA has organized a webinar on 13th December on RAG and AI Chatbots to give an overview -How is NVIDIA building AI Chatbots Using RAG? This article shall give you a highlight on the key aspects of the webinar discussion.
Businesses can’t afford to ignore the increasing importance of artificial intelligence (AI) in today’s fast-paced technology market; it’s now an absolute must. A lot of people are using large language models (LLMs), yet there are certain problems with them. They have problems grasping domain-specific concepts and are susceptible to hallucinations. AI has taken a giant step forward with retrieval-augmented generation (RAG), which allows companies to harness the power of real-time, domain-specific data in ways that were before impossible.
What Is RAG in the Chatbot?
At the very least, the method may be traced to the early 1970s. Apps that employ natural language processing (NLP) to retrieve text were prototyped at that time by information retrieval academics. They first focused on specific themes like baseball.
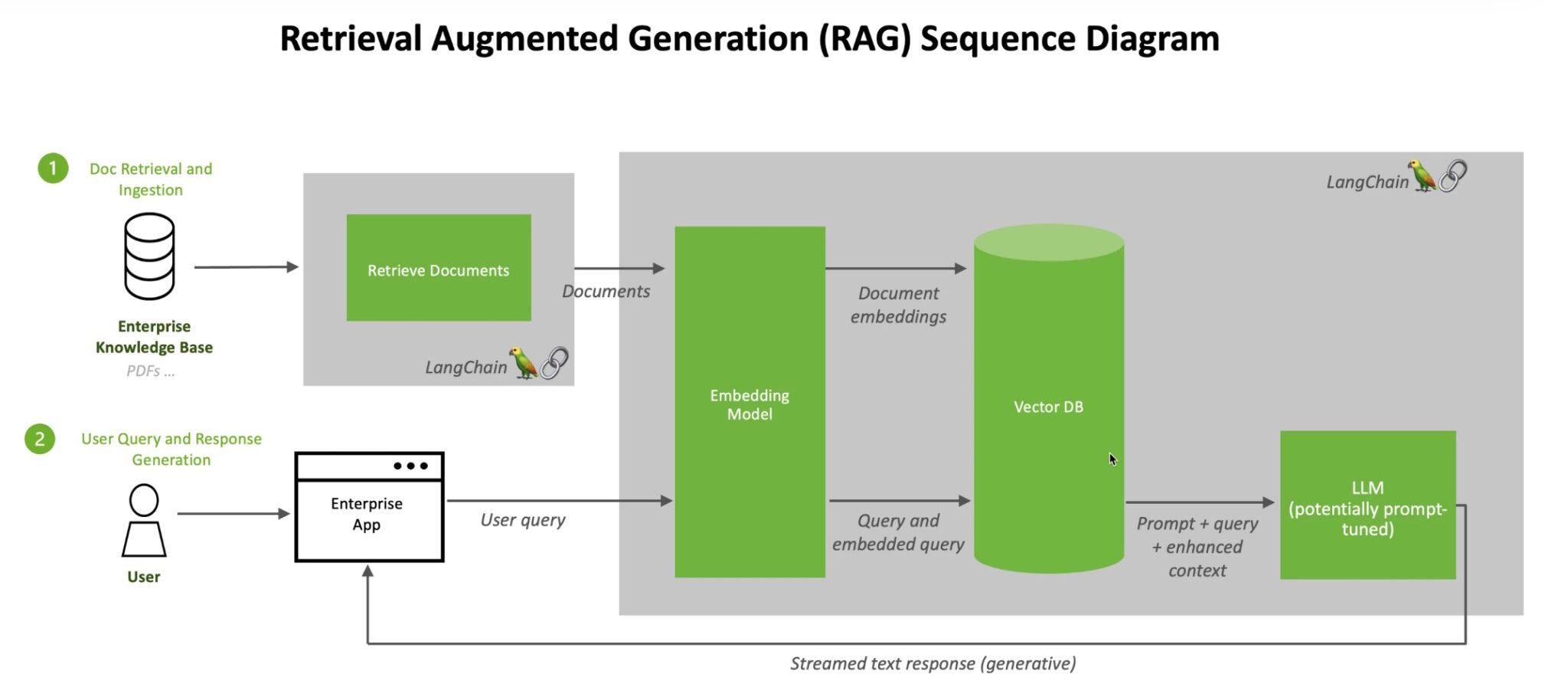
A method for improving the precision and consistency of generative AI models by supplementing them with data obtained from external sources is known as retrieval-augmented generation (RAG). Put simply, it addresses a shortcoming in the operation of LLMs. Secretly, LLMs are just neural networks, and their complexity is usually quantified by the number of parameters they employ. The main patterns of human word-to-sentence formation are largely represented by an LLM’s parameters.
Because of their extensive knowledge, which is also known as parameterized knowledge, LLMs can answer broad requests very quickly. On the other hand, it isn’t useful for people who want to learn more about a particular or current subject. One architectural strategy that can make large language model (LLM) applications more effective is retrieval augmented generation (RAG). To do this, pertinent information or papers about a job or inquiry are retrieved and sent to the LLM to serve as background.
Getting Started With Retrieval-Augmented Generation (RAG)

An artificial intelligence methodology for retrieval-augmented generation was created by NVIDIA to assist users in getting started. It comes with everything customers need to build apps using this new approach, including a prototype chatbot.
The process incorporates NVIDIA TensorRT-LLM and NVIDIA Triton Inference Server, two platforms for executing generative AI models in production, together with NVIDIA NeMo, a framework for creating and tailoring such models. All of these programs are a part of NVIDIA AI Enterprise, a platform that helps companies build and launch AI systems faster while providing the stability, support, and security that these systems require.
Data movement and processing on a vast scale is necessary for optimal RAG workflow performance. With 8 petaflops of computational power and 288 GB of fast HBM3e memory, the NVIDIA GH200 Grace Hopper Superchip is perfect; it can achieve a 150x speedup compared to a CPU. Companies may construct a broad range of assistants to support workers and customers after they are accustomed to RAG. They can integrate off-the-shelf or bespoke LLMs with internal or external knowledge sources. There is no need for a data center to run RAG. Thanks to NVIDIA software, which makes a wide variety of apps accessible on laptops, LLMs are now available on Windows PCs.
What Is the Difference Between a RAG and a Chatbot?
Key Take Aways From This Webinar
![]() Transformations created by the use of chatbots, AI assistants, and copilots
Transformations created by the use of chatbots, AI assistants, and copilots
 Transformations created by the use of chatbots, AI assistants, and copilots
Transformations created by the use of chatbots, AI assistants, and copilots- How is RAG (retrieval-augmented generation) a powerful technique driving generative AI applications?
- Key use cases of AI-powered assistants
- How to build safe, secure AI chatbots that stay on task?
Speakers
Read: 4 Common Myths Related To Women In The Workplace
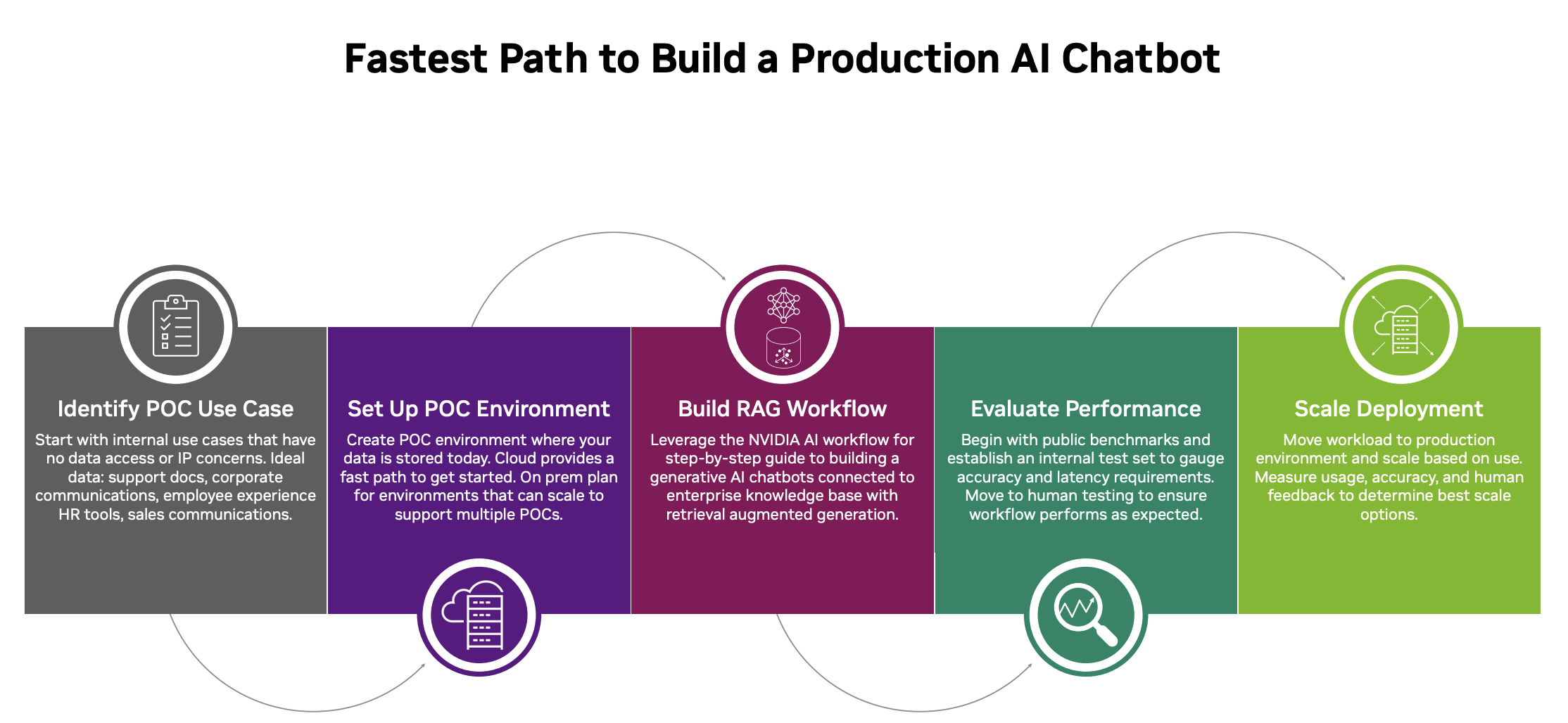
NVIDIA’s AI Workflow
NVIDIA AI Workflows consist of a bundled product that includes the AI framework and the necessary tools for automating a cloud-native solution. AI workflows have pre-built components that are designed for business use and adhere to industry standards for reliability, security, performance, scalability, and interoperability. These components also provide flexibility for customization.
An ordinary procedure could be like the diagram provided below:

Each process in this stack includes opinionated direction and sample components at every tier. Additionally, information is provided on how to connect the AI solution with these components.
Hardware
The utilization of NVIDIA AI Enterprise necessitates the use of GPU-accelerated hardware or cloud instances that are compatible. Each process is accompanied by precise needs and specifications.
Infrastructure and Orchestration
The NVIDIA Cloud Native Stack serves as an illustrative Kubernetes distribution for deploying and orchestrating workloads.
Supporting Software
The NVIDIA Cloud Native Service Add-on Pack facilitates the deployment of a collection of components that are essential for performing various services commonly needed in a production enterprise setting, including authentication/authorization, monitoring, storage/database, and more.
Applications
The example microservices are presented as a sequence of Helm charts and tailored containers, which are deployed as part of the workflow. Their purpose is to showcase the process of customizing and constructing an AI application using NVIDIA frameworks, as well as integrating this application with other microservices and enterprise software components.
[To share your insights with us, please write to sghosh@martechseries.com]
Comments are closed.