
Microsoft AI Expands Azure Cognitive Services Computer Vision’s Image Captioning Capabilities
Microsoft’s AI development team has announced a new AI-based image captioning offering as part of Azure Cognitive Services. The latest set of Azure Cognitive Services brings AI within reach of the developers, enabling them to build an AI system that can automatically generate captions for images. The latest Computer Vision-based cognitive intelligence system is so accurate that Microsoft researchers are hailing it as a breakthrough in Machine Learning-based Image Captioning.
Microsoft AI has revealed that they have achieved mastery over the five major human parities despite facing a daunting battle against the COVID-19 pandemic.
The human parities are in:
- Speech Recognition
- Machine Translation
- Conversational Question Answering,
- Machine Reading Comprehension
- Image Captioning Human Parity
Why We Need Image Captioning?
Lijuan Wang, a principal research manager in Microsoft’s research lab in Redmond explains why AI-based image captioning is so vital for the future of digital conversations.
Lijuan says, “Image captioning is a core challenge in the discipline of computer vision, one that requires an AI system to understand and describe the salient content, or action, in an image. You really need to understand what is going on, you need to know the relationship between objects and actions and you need to summarize and describe it in a natural language sentence.”
Microsoft is expecting the latest improvements to add to Azure Cognitive Services and other Azure AI products and services. The AI team at Azure built the AI system to generate captions for images that are, in many cases, more accurate than the descriptions people write. This attempt will push Microsoft to make its products and services inclusive and accessible to all users, incorporated into Seeing AI and Microsoft Word and Outlook, Windows and Mac, and PowerPoint for Windows, Mac and web.
Recommended: Cognitive Bias at Workplace Negatively Impacts Employer’s Decision-making
How Image Captioning works within Azure Cognitive Services
In normal web search, the image captioning is fairly straightforward, where the developers or editors can generate a photo description by simply adding an “ALT TEXT”. This practice is very common in usual webpage designing and search optimization operations. But, it leaves a big gap when it comes to achieving accuracy of details for the visually-impaired population.
To understand Azure Cognitive Service’s latest AI ML image captioning offering, we have to understand how pre-training of image detection and computer vision work together.
The key capabilities include –
Novel object captioning (NOC)
NOC is used to auto-generate image captions based on human-computer interaction and image-language understanding. AI researchers have developed “nocaps” to solve the challenges that the NOC technique poses in image captioning models.
Vision and language pretraining (VLP)
VLP is a very effective cross-modal representation learning which can be further fine-tuned to improve the performance on image captioning such as Object-Semantics Aligned Pre-training or better referred to as ‘OSCAR.’
To learn more about OSCAR, please click here.
Azure Cognitive Services’ image captioning is an industry-benchmark. It is built on “nocaps” concept that leverages the novel object captioning at scale. “The benchmark evaluates AI systems on how well they generate captions for objects in images that are not in the dataset used to train them,” explains Microsoft AI.
Here’s how the Microsoft Azure AI team showed the effectiveness of their Computer Vision-based image nocaps model

“Image captioning systems are typically trained with datasets that contain images paired with sentences that describe the images, essentially a dataset of captioned images.”
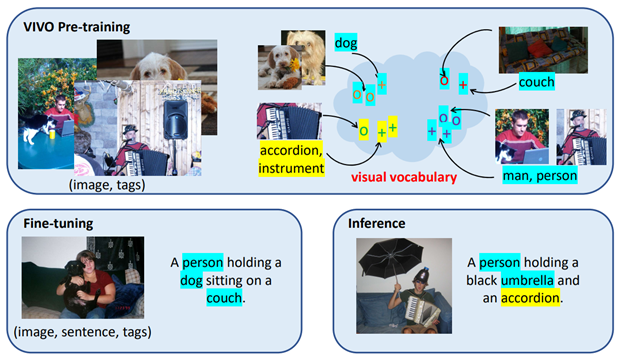
Pre-trained AI Tags for Image Captioning
Microsoft team pre-trained a large AI model to build the world’s most advanced ‘visual vocabulary’. It could help visually impaired people to understand the type of online content. These could be synced with Seeing AI talking camera app or a text reading app for blind people. Computer vision, integrated with image captioning techniques and conversational AI makes Azure Cognitive Services so advanced in the modern context of delivering highly contextual customer-centric experiences, mobile app personalization, gamification and e-commerce product search.
Tagging images with accurate keywords is more effective in building an AI dataset for a pre-trained image captioning model. It can be understood from Microsoft AI’s generic explanation as discussed below.
“The visual vocabulary pre-training approach is similar to prepping children to read by first using a picture book that associates individual words with images, such as a picture of an apple with the word “apple” beneath it and a picture of a cat with the word “cat” beneath it.”

Watch this informative YouTube video on “Microsoft AI breakthrough in automatic image captioning”