
How Dataloop’s Approach To Human-In-The-Loop ML Boosts Project Efficiency
Artificial intelligence is at the forefront of the rapid technological progress the world is witnessing. Organizations across all business sectors have committed significant resources to AI development, as they seek to expand the traditional boundaries of their applications.
Gartner predicts that companies will increasingly seek to democratize AI usage to bring value to their customers, salespeople, assembly line workers, and business executives. As AI’s benefits are becoming apparent, organizations are now grappling with a new issue: AI scalability.
Edge case exceptions, complex data management, and the need to continuously teach models make scaling AI a tough task. As organizations run into the limits of traditional infrastructure, the below three processes, which are key aspects of Dataloop’s platform, can help you scale your AI projects.
Increase Automatic Annotation
The biggest challenge facing AI scaling operations is the need for data preparation and annotation. Using manual annotation for relatively small sets of data during the testing phase might seem viable, but preparing raw data at scale is a tough task.
Enhanced by active learning, Dataloop’s automated annotation engine removes the need for large teams of human annotators to review entire datasets. Automation also transforms the process into a quality assurance one, with manual intervention needed only when the system fails to recognize objects – or when confidence levels dip below whatever threshold project managers determine.
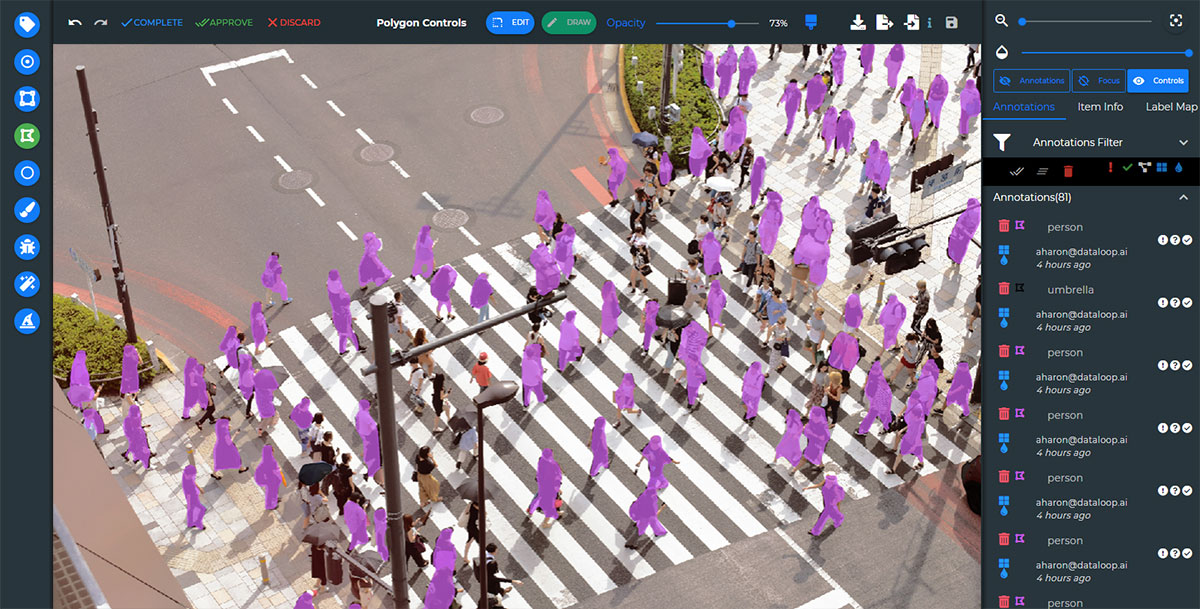
The result is that annotation teams can devote most of their time to identifying and mitigating edge cases. All AI applications will inevitably encounter scenarios they don’t recognize, and they won’t perform as expected.
While some edge case misidentifications might be harmless, they can potentially cascade into bigger problems. For instance, an AI engine that misidentifies a human being for a natural object might be humorous when used in an image search application. However, migrate this to a self-driving truck, and the risk is enormous.
Dealing with edge cases requires human intervention, and eliminating tedious annotation tasks as much as possible is the key to processing them in a manner that efficiently empowers algorithmic autonomy. Edge case instances increase exponentially at scale, so prioritizing your annotation team’s time is critical for success.
Aside from product development, increased annotation efficiency will directly impact your bottom line through greater ROI on time spent scaling your AI application.
Smarter Data Ops
AI adoption puts companies at odds with traditional infrastructure solutions. Traditional RDBMSs run into issues when dealing with data that is almost 100x the volume of traditional commercial IT applications. Increased data volume also brings governance and operational issues.
The result is a data ops team overloaded with tasks relating to access, quality, and enabling cross-functional collaboration. This is why Dataloops allows you to natively integrate your data management facilities directly with your AI annotation. With both functionalities under one roof, collaboration becomes a breeze, and data ops members can upload new sets of data and put them to use seamlessly.
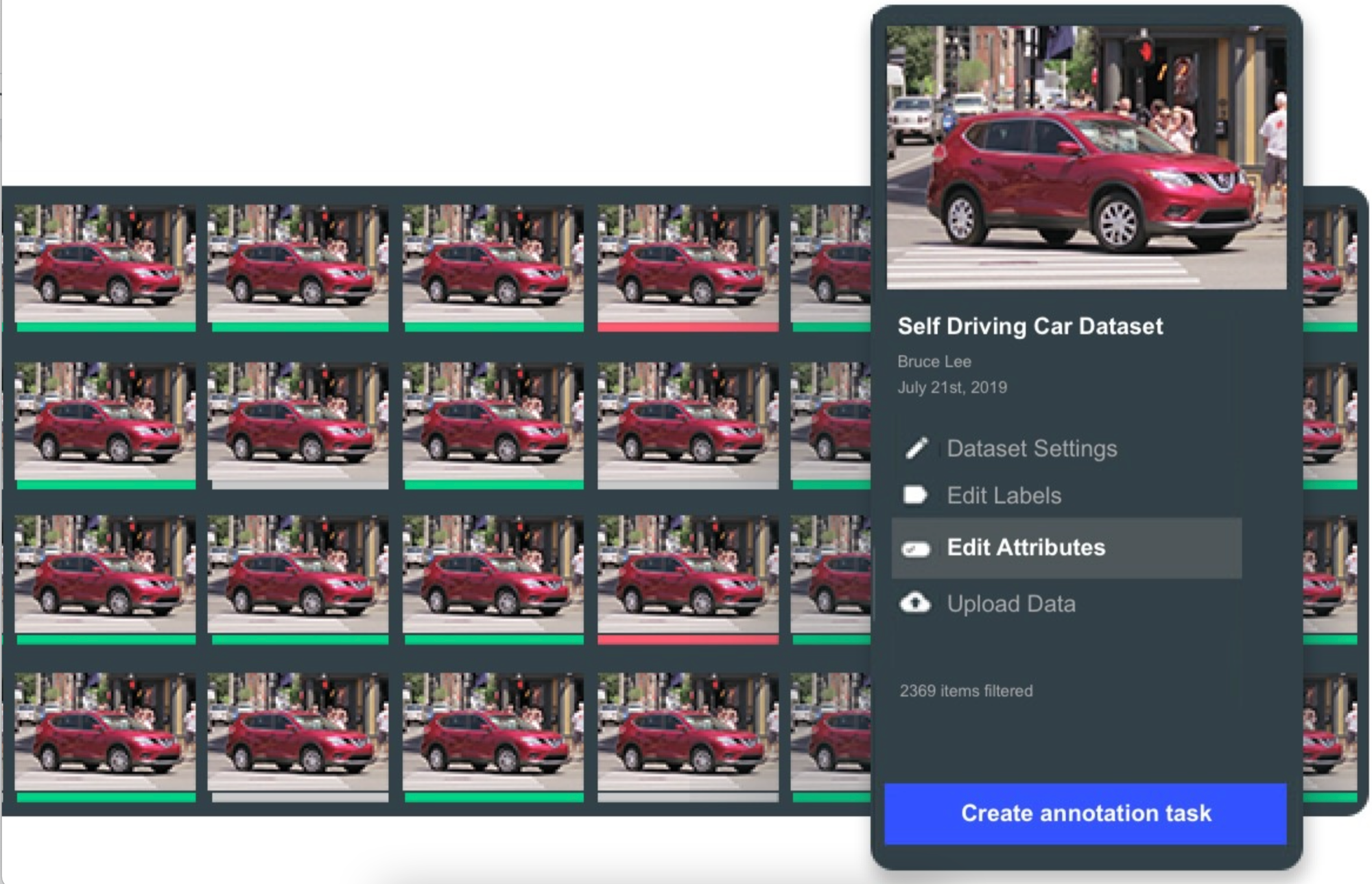
Another powerful solution is to integrate and automate a subset of your data ops procedures directly from code via RESTful APIs and Python SDKs. This process makes it easy for your data ops team to create and maintain complex ontologies, version datasets, and control data quality.
AI datasets tend to have a large number of variables, and this makes installing QA processes to review annotations and relationships essential. Savvy project managers know how to identify common issues and prioritize reviews based on annotation or item-specific parameters. Before customizing your metadata, however, make sure you achieve team consensus on label taxonomies to avoid over-customizing your data and creating more headaches for yourself.
It’s also important to recognize the business-facing challenges that AI brings. Your data ops team will have to be prepared to answer questions about unintended business consequences. For example, if your application detects a new customer behavior pattern, it might return an incomprehensible result since it hasn’t seen this in testing.
You will have to evaluate whether this warrants expanding your application’s scope or writing it off as an exception. Whatever your choice is, your data ops team has to be in the loop to explain results to business users who won’t always understand the technicalities of edge cases and exceptions.
Create Smart Data Pipelines
Unlike traditional IT projects where you can release code into production and then handle exceptions, AI development is a constant process. Models need high-quality data and evolve on the job constantly.
No matter how good your test datasets are, real-world data and your application’s reaction to it are what builds confidence levels.
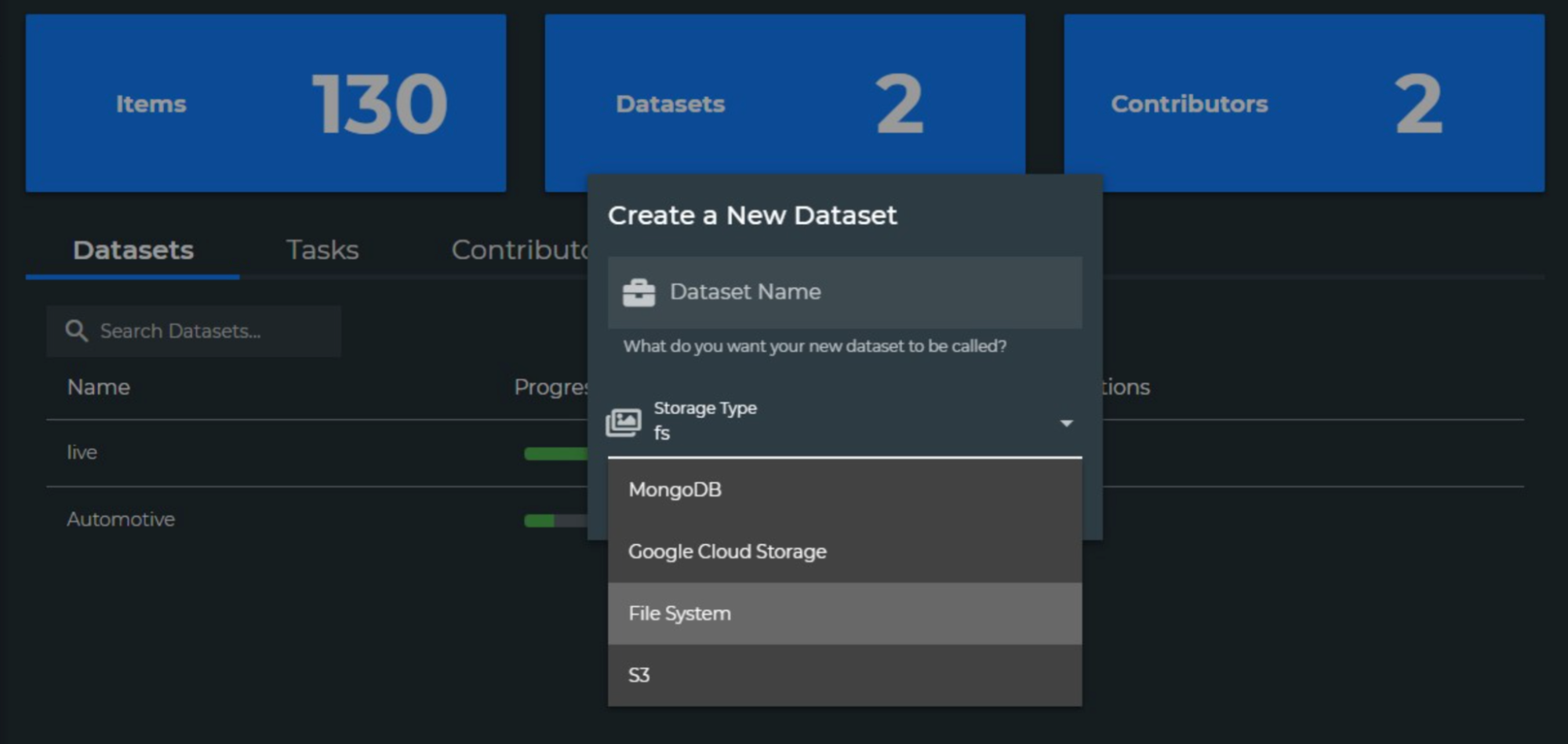
Using Dataloop, you can automate the data pipeline through Python SDKs and custom apps, creating QA processes through bespoke plugins and HITL feedback loops. A key part of the learning process is reacting to unexpected patterns or changing patterns. With Dataloop’s ecosystem, you can set up custom event-driven plugins that trigger learning loops.
For instance, once your system detects new behavior, you can execute automated annotation processes on raw data, validate edge cases and exceptions using HITL feedback, and feed this data to your model through a custom pipeline.
It’s generally a good idea to use collaborative HITL processes to validate confidence levels for new datasets at all times. AI systems are intelligent but for now, they’re only as good as the humans that back them up.
Constant Development
AI systems are improving rapidly, but the reality is that most of them still fail the Turing test.
Collaboration throughout your organization is the key to extract an AI application’s promise. Combine your collaborative efforts with these three processes, and you’ll manage to reduce the size of challenge you face when scaling AI in your organization.
Comments are closed.