
The Mechanical Bard: Creating Shakespearean Sonnets with an Explainable Machine Learning Approach
Sonnets are a unique form of poetry with specific rhyme and meter constraints. With the creative powers of AI, automated sonnet generation brings the timeless art of poetry into the realm of machines.
Researchers from Duke University, Durham, NC, explored the fascinating world of sonnets and put together – The Mechanical Bard: An Interpretable Machine Learning Approach to Shakespearean Sonnet Generation. The team included Edwin Agnew, Michelle Qiu, Lily Zhu, Sam Wiseman, and Cynthia Rudin Duke.
With meticulous algorithms and linguistic finesse, these digital bards craft Shakespearean sonnets that echo the beauty of human expression.
The Goal of the Paper
The goal was to create Shakespearean sonnets that resemble those written by humans, adhering to the genre’s defined constraints and featuring lyrical language and literary devices. Instead of training massive models that struggle to meet these constraints, the team took a different approach. They used part-of-speech (POS) templates inspired by Shakespeare’s sonnets, combining them with thematic words and a language model. The result is a method that produces high-quality sonnets with sophisticated language, comparable to human-written poetry.
The Methodology
![]() GPT-2 as the Foundation: Imposing Poetic Constraints
GPT-2 as the Foundation: Imposing Poetic Constraints
 GPT-2 as the Foundation: Imposing Poetic Constraints
GPT-2 as the Foundation: Imposing Poetic ConstraintsThe approach revolved around utilizing a pre-trained language model, specifically GPT-2, as the foundation. They then imposed strict constraints during the generation process, ensuring that the resulting text adheres to various poetic requirements.
These constraints can be categorized into two main types: hard constraints, such as syllable count, and soft constraints, which focus on maintaining a poetic tone. By applying these constraints, our methodology ensures that the generated text meets the desired poetic criteria.
Read: The Future of CRM – 10 AI-Driven Platforms Redefining 2023
Exploring the Power of Grammar Templates
A key aspect of the approach involved the use of carefully crafted grammar templates. Drawing inspiration from existing sonnets, they developed a collection of approximately 120 templates that capture the part-of-speech structure of poetic lines. Each template has the potential to generate countless unique poetic lines. For instance, the line “The beauty of life on a lonely sea” can be represented by the template “THE NN OF NN ON A JJ NN.”
The flexibility of these templates allowed for a wide range of expressions, but simply adhering to the templates is not sufficient for creating poetry. The same template can yield lines with distinct meanings, such as “The tree of anguish on a stormy night,” or even nonsensical phrases like “The fork of ant on an unpacked transfer.” Additionally, a subset of these templates is specifically chosen for initiating stanzas.
Sonnet Metrics: The Power of Iambic Pentameter and Rhyme Schemes
Sonnets have two key distinguishing features: iambic pentameter and a specific rhyme scheme (ABAB CDCD EFEF GG).
To identify iambic pentameter, we use the CMU Pronouncing Dictionary, which provides syllable count and stress information for words. Stressed syllables are represented as ‘1’, and unstressed syllables as ‘0’.
For example, “The beauty of life on a lonely sea” would be represented as ‘0 10 1 0 1 0 10 1’. They created a tree-like structure based on the part-of-speech (POS) tag for each word, allowing them to determine the possible syllable choices and pronunciations for each line while ensuring the last syllable matches the rhyme scheme.
Fine-tuning and Constrained Beam-Search Techniques
To generate sonnet lines, we employ a language model. Specifically, they fine-tune GPT2 on a substantial collection of over 15,000 poems, including a smaller set of sonnets.
- The generation process involved a constrained beam search, where each step only allows the production of valid tokens based on the established constraints.
- This approach is reminiscent of previous methods used in sonnet generation, although their approach differs in terms of model selection and the direct enforcement of constraints.
- They also compared the quality of generation using a GPT-2 model that hasn’t undergone fine-tuning.
Thematic Word Choice – Leveraging Synonyms and Embeddings
To ensure the poem aligns with the user’s chosen theme, they included a relevant excerpt from a poem as additional context for GPT-2 during the generation process. This excerpt is selected by searching for synonyms of the theme word using the WordNet synonym database and then selecting lines from a poem collection that contain at least one of these synonyms.
They also filtered the vocabulary by removing words with a cosine similarity of less than 0.5 to the theme word, using FastText word embeddings. This helps avoid inappropriate words, like “algebra,” in poems with nature-themed themes like “forest.”
Generation Procedure
First, the user provides a theme word, a beam search parameter (b), and the number of templates sampled per line (k). Using a specific method, we select a seed.
For each line, we randomly sample k templates. With each template, we employ a modified beam search to generate the line. This modified search maintains b hypotheses per line, eliminating tokens that violate our strict constraints (POS, meter, and rhyme), and selecting the b best next-tokens for each of the k templates.
Read: 5 Ways Netflix is Using AI to Improve Customer Experience
These candidates are ranked using our custom scoring function, and the top k × b proceed to the next stage. This iterative process ensures that the generated lines align with the input templates. If none of the k×b lines surpass a specific threshold, a new template is chosen, and the line generation restarts. Otherwise, the process continues until the entire poem is completed.
Poetic Devices
To enhance the poetic quality of our poems, we adjust our scoring function by considering various factors. These factors include alliteration, repetition, and internal rhyme. Alliteration happens when words in a line start with the same letter. Repetition occurs when a word appears multiple times in the poem, and internal rhyme is when two words rhyme within a line. We assign weights to these factors by generating lists that track the occurrences of specific letters (A⃗), tokens (T⃗), and rhyming words (R⃗). The final token distribution takes into account the language model’s next-token distribution (P˜) as well as user-defined parameters (αA, αT, αR) that determine the emphasis on alliteration, repetition, and internal rhyme during generation.
Post-processing
Once a poem is finished and all 14 lines meet a predetermined threshold, a few minor adjustments are made. These adjustments address common errors made by GPT-2, such as neglecting to capitalize the word ‘I’ or failing to capitalize after punctuation marks.
Experiments
- The sonnets created by the team were compared with model-generated and human-written sonnets.
- Baselines were established to generate complete sonnets based on user-provided themes.
- Competitors were narrowed down to Benhardt et al. (2018) and PoeTryMe (Oliveira, 2012).
- Human-written sonnets from sonnets.org were selected, considering alignment with our five themes.
- Values for k, b, and repetition penalties were chosen through internal analysis for optimal testing.
- Respondents evaluated pairs of sonnets, comparing our sonnets with competing models or human-written sonnets using the same theme.
- Assessment categories included theme representation, poeticness, grammar, emotion, and the likelihood of being human-written.
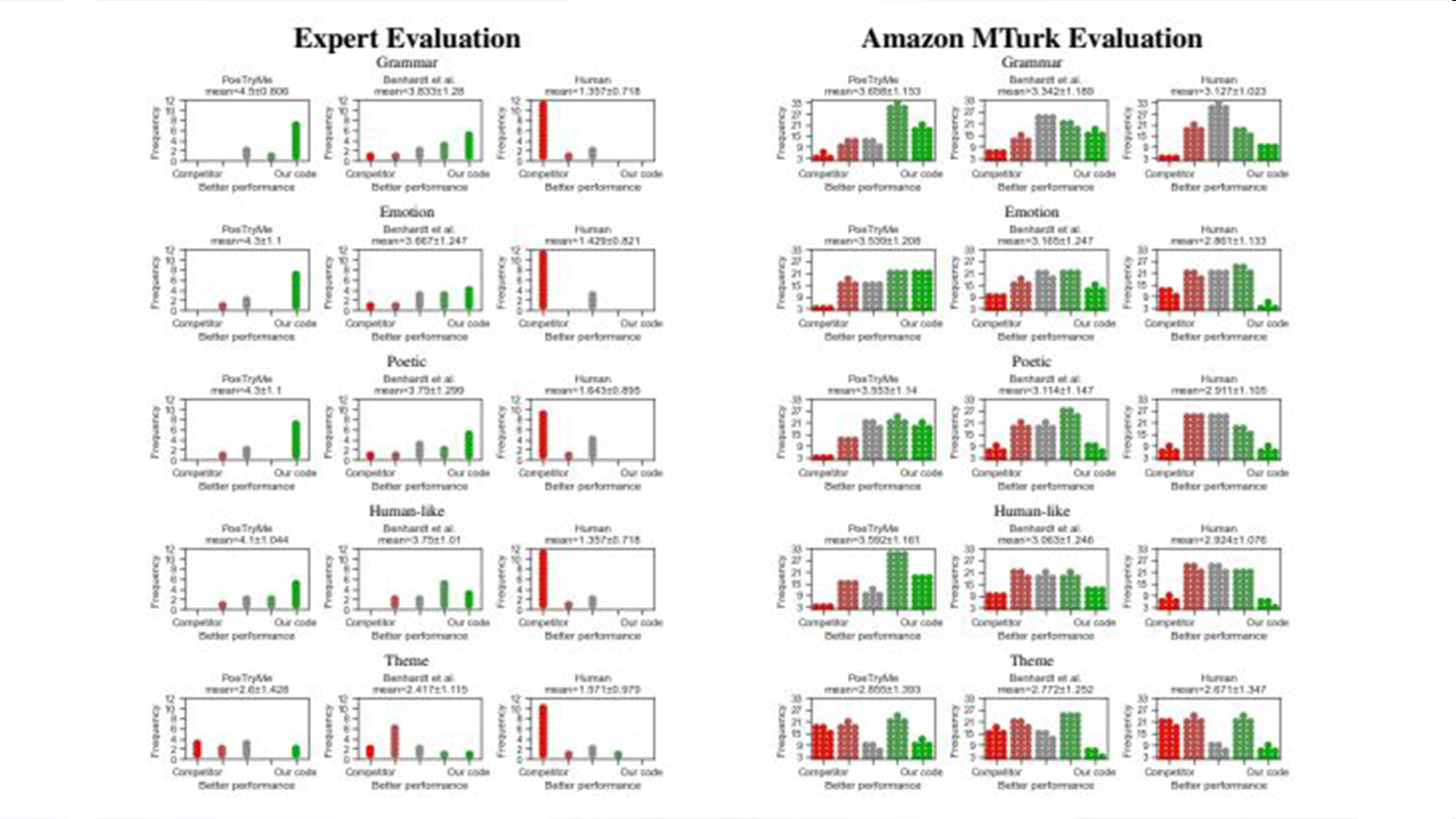
Expert Evaluation: Sonnets Outperform Competitors in Key Categories
We asked six faculty members and students from an English department to evaluate our sonnets. The results (shown in Figures 3 and 5) clearly demonstrate that our sonnets are superior to PoeTryMe in all categories except theme, with a high level of statistical significance (p<0.006). Compared to Benhardt et al., our sonnets outperform them in all poetic aspects except theme and emotion, also with statistical significance (p<0.05). However, it’s worth noting that even though our computer-generated poems were impressive, respondents could still easily distinguish them from human-written sonnets.
![]() Amazon MTurk Evaluation
Amazon MTurk Evaluation
 Amazon MTurk Evaluation
Amazon MTurk EvaluationIn addition to expert evaluation, we also utilized Amazon MTurk to evaluate our poems on a larger scale. The results, as shown in Figures 4 and 6, demonstrate our superior performance compared to competitors across various categories. While it is not surprising that our computer-generated poems couldn’t surpass human-written poems, we can confidently say that human-written poems outperformed ours primarily in the theme category. However, it’s worth noting that our poems performed better than human-written poems in terms of grammar, although the statistical significance was relatively low. This highlights the quality of our strictly constrained beam search in generating grammatically sound poems.
Ablative Evaluation
We also conducted studies to analyze the effectiveness of two important aspects of our method: line templates and the fine-tuned GPT-2 language model. To evaluate their impact, we generated two sets of poems: one using the fine-tuned GPT-2 model without templating, and another using the untrained GPT-2 model with templating. We then employed Amazon MTurk to compare the quality of each set based on the same criteria as our previous experiments. The results, as shown in Figure 11, highlight the importance of combining both the fine-tuned model and templating for generating higher-quality sonnets. Our poems incorporating both factors outperformed the ablative sets in various ways, emphasizing the critical role of using templates to create exceptional poems.
Limitations
Though our method produces full sonnets that are more impressive than all previous approaches, it is still not at the level of human-generated poetry. It is not clear how to achieve this level, whether it would be using massive large language models, or through our general approach, which is to bend those models around an interpretable framework that knows the rules that sonnets obey. Certainly, our approach requires a lot less data – even if one used all the sonnets that have ever been written to train a language model, it is unclear that the language model would learn the very specific rules required of sonnets. However, there may be other ways to obtain these constraints that have not yet been developed.
Conclusion
The novel approach to generating high-quality poems stands out due to its use of POS templating, which ensures logical syntactical structures while adhering to the necessary constraints of a sonnet. The method offers great versatility, allowing for adjustments in poetic elements such as alliteration, internal rhyme, repetition, and theme to encourage creativity in the generated output.
Through rigorous evaluations involving expert evaluators and MTurk participants, the model has demonstrated its superiority over similar competitors. Although the poems, like those of most computer-generated poetry, can be distinguished from human-written poems, our fine-tuned GPT-2 model requires significantly fewer computational resources compared to newer GPT models. Furthermore, while we were unable to directly compare our model to ChatGPT, our preliminary evaluation suggests that ChatGPT tends to produce generic poetry. In this specific application, our model presents a cost-effective and relatively high-quality solution for generating sonnets.
Like any form of neural generation, there are valid concerns regarding the potential for misinformation and the generation of toxic content. While these concerns also apply to poetry generation to some extent, our approach significantly mitigates these risks. By implementing strict constraints and using a limited vocabulary, we minimize the likelihood of generating problematic or harmful text. Our focus on maintaining rigorous control over the generation process ensures that the output remains within the intended boundaries, reducing the potential for misinformation or toxicity.
[To share your insights with us, please write to sghosh@martechseries.com].
Comments are closed.