
DeepNash and the World of Model-free Multi-agent Reinforcement Learning (RL)
DeepMind team has managed to train an agent that can play and beat other AI Bots Stratego—the world’s most complex board game with upto 97% win-rate. The agent is called DeepNash, a powerful Reinforcement Learning-based multi-agent that is built on game theory, neural networking and deep learning capabilities.
Stratego, the new-age strategy board game has piqued the interest of AI researchers around the world. It has been regarded as one of the most-complex modern-day battle strategy board games with a very density of incomplete information. For decades, AI scientists have been trying to teach computers play this complex game, but unlike chess, the Reinforcement learning (RL) algorithms fell short of the expectations. But, now, DeepMind AI team has built a semi-supervised multi-agent reinforcement learning algorithm to teach machines how to play and win this amazing game of brains. The DeepMind AI researchers call this autonomous agent RL model- -DeepNash. DashNash is a model-free multi-agent based on Regularized Nash Dynamics (R-NaD), combining the advancing algorithms of deep neural networks with ᵋ – Nash Equilibrium (epsilon equilibrium or near-Nash equilibrium) and advanced deep learning capabilities.
More from DeepMind AI: DeepMind’s AlphaFold2 Solves 50-year Old Protein Fold Challenge
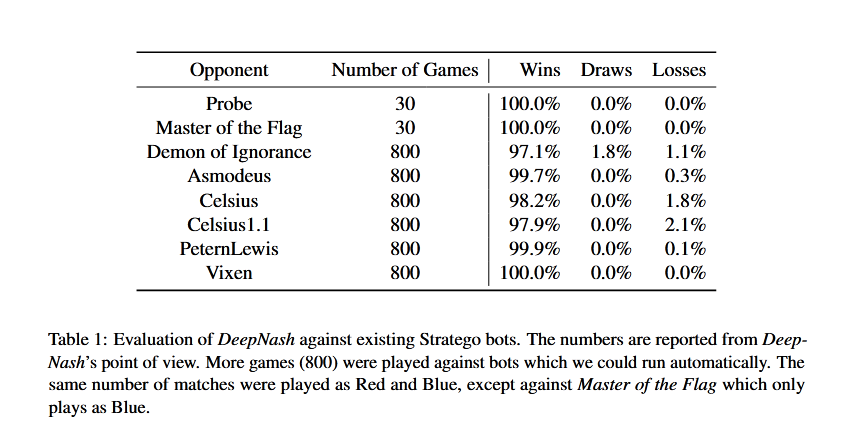
Effectively, DeepNash has a very high rate of winning percentage against all the other AI-based bots that have been trained to play Stratego. DeepMind found DeepNash has a very high win-rate performance against AI bots (97%) as well as human players (84%) on Gravon. platform. In 2022, DeepNash emerged among the Top-3 players in the all times leaderboards.
DeepNash played Stratego against these AI bots.
- Probe
- Master of the Flag
- Demon of Ignorance
- Asmodeus
- Celsius
- Celsius 1.1
- PeternLewis
- Vixen
Results of their competition have been published by DeepNash below.
Multiagent Reinforcement Learning
Perfect Information Games, Imperfect Information Games and the World of Model-based Reinforcement Learning
To understand the world of how information is used in games, AI researchers have to master the Game Theory. Game Theory is a mathematical approach to develop, analyze and understand how different mathematical models can be used to identify the actions and engagements among rational agents/ rational beings such as a human, a machine, software, or a bot. the first mention of Game Theory or related strategies was made in 1928, when famous polymath John Von Neumann published the paper, “On the Theory of Games of Strategy.” In 1944, he followed up on his paper by co-authoring “Theory of Games and Economic Behavior” with Oskar Morgenstern. However, the real push to Game Theory came in the the 1950s when John Nash proposed “Nash Equilbrium” for mixed strategies involving n-players, non-zero-sum games. Between 1950s and 2000s, scientists and mathematicians worked in sync to develop many theories and approaches to understand the strategies involved in different games (cooperative versus non-cooperative, symmetrical vs. unsymmetrical, sequential vs. simultaneous, and perfect information vs. imperfect or incomplete information) and Bayesian games.
Tic-tac-toe, Go, Chess and Checkers are examples of perfect information sequential games. On the other hand, Stratego, like Poker and Bridge (or most card games) is an incomplete / imperfect information sequential game. Multiplicity of imperfect information models could give rise to more game models such as Bayesian, Combinatorial and Evolutionary and Infinite long games.
In a imperfect information sequential game like Stratego, there are 10535 decision nodes or possible states in the Decision Tree.
Unlike in Chess or Go where it is possible to train an agent using Nash Equilbrium in a model-based RL it is impossible to do the same for Stratego. There are two reasons for this limitation with model-free RL models. First, Stratego is an imperfect information game. Second, search options for Stratego is intractable as Nash Equilibrium can’t be used to estimate private information in public states. This limitation is solved by adopting R-NaD, an advanced RL approach used to train a model-free agent using Nash Equilibrium. These approaches can be used to train multiple agents and hence, DeepNash is a multi-agent model-free RL algorithm.
How DeepNash Works?
DeepNaskh leverages the idea of regularization in R-NaD algorithm achieved through deep neural network. R-NaD, the core training model-free RL algorithm is implemented using Deep Neural Network, and then fine-tuned to remove probability mistakes.
DeepNash is able to hide information from other opponents in an effective manner by adjusting trade-offs in its favor. Agent is also able to deceive and bluff opponents when required — a highly advanced model-free RL training that only DeepNash has been able to achieve using R-NaD and deep residual neural network.
C********* to learn more about DeepNash and its performance against other bots and human agents.
Comments are closed.