
Synthetic Data
Modern chatbots rely on large language models (LLMs) that have been pre-trained on raw text to acquire an abstract understanding of language. This sets them up for rapid task acquisition after seeing detailed, labeled instructions during alignment. However, reliable instructional data is not easily accessible. Humans can’t afford to make it, and it usually doesn’t have the breadth and depth that chatbots require to handle uncommon, complex, or hard situations. Although synthetic data is significantly more affordable, it frequently has the same problem of being monotonous.
Read: Optimizing IBM’s Cloud-Native AI Supercomputer for Superior Performance
LLM Developers
- LLM developers may specify the information and abilities they wish to imbue their chatbot with using IBM’s taxonomy-driven data-generation approach. To help developers find and fill in knowledge gaps, the taxonomy organizes the LLM’s current abilities and knowledge in a systematic, hierarchical fashion.
- A second LLM, the teacher model, uses the taxonomy to generate task-specific question-and-answer pairs that are considered high-quality instructions. Consider the following scenario: you would like a chatbot to compose an email outlining the company’s third-quarter financials and send it to the CEO. The ideal candidate will have experience with financial statements, be proficient in basic arithmetic and reasoning, and have the ability to concisely and persuasively describe financial facts in an email. The LLM developer may begin this made-up scenario by uploading the company’s financial accounts together with multiple sample calculations for corporate earnings. The financial records would serve as the basis for the instructions generated by the teacher model. In that manner, new instructions can be made if accounting regulations change. Another way is for the teacher model to tell the base LLM how to figure the earnings.
- The third option involves the developer providing example earnings-report emails, which the teacher model then uses to train the base model to compose the desired email.
Read 10 AI In Manufacturing Trends To Look Out For In 2024
Large-scale Alignment for chatbots (LAB)
LAB was also instrumental in helping IBM refine its own Granite models on IBM Watson with an eye toward enterprise application. Large-scale Alignment for chatbots (LAB) is IBM’s latest offering in this space. It’s a way to construct synthetic data for the jobs you want your chatbot to do and to incorporate new skills and knowledge into the base model without erasing its previous learnings. Training LLMs normally take a lot of time and money, but with LAB, LLMs can be significantly enhanced with much less effort and expense.
Read: Top 15 AI Trends In 5G Technology
Knowledge, foundational skills, and compositional skills that build on knowledge and foundational skills are the three main categories into which instruction data is separated according to IBM’s taxonomy. Knowledge of accounting, proficiency in mathematics, and the ability to write and reason coherently are all possible pieces of information that might be required in this case. The instructor model would iteratively conduct quality control on its outcomes while generating instructions for each category. The data that the instructor model produced is also subjected to quality control assessments. It eliminates irrelevant inquiries and directions with inaccurate information by being its own harshest critic. The figure below has been taken from the website of IBM.
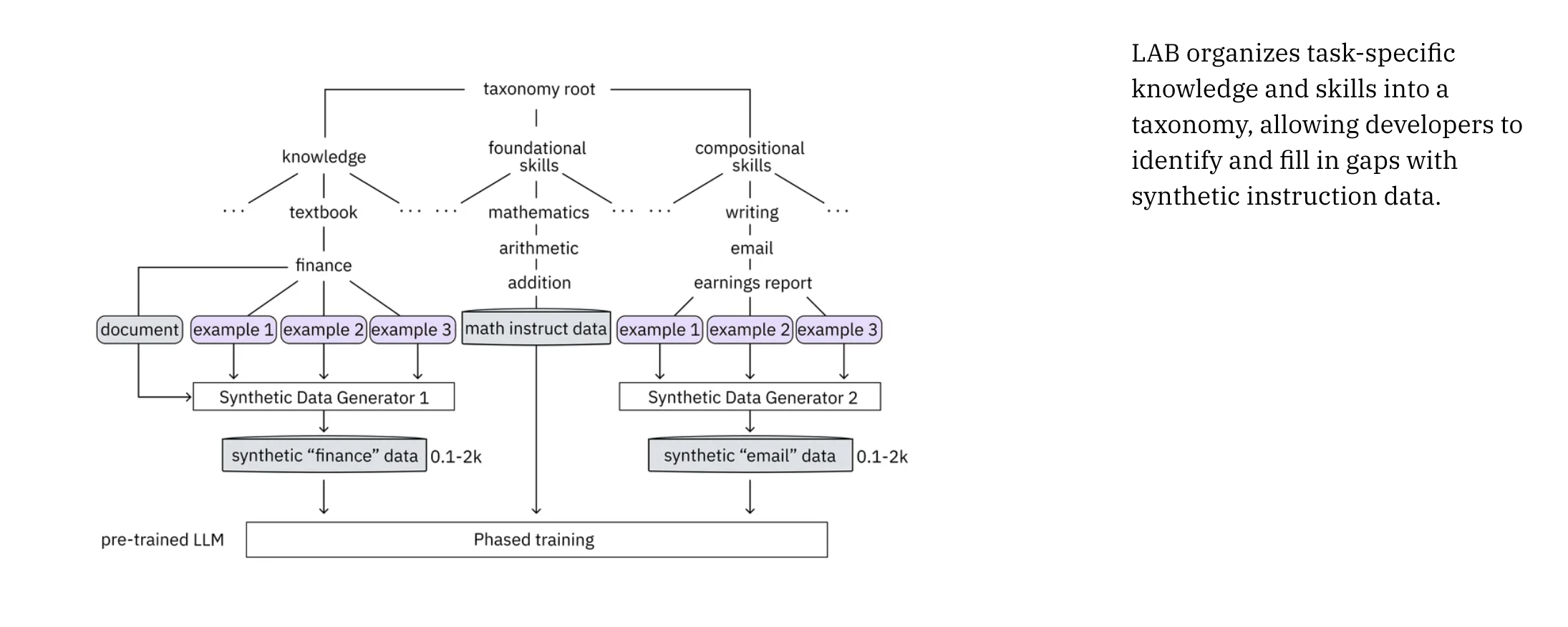 The approved instructions are then divided into three sections: knowledge, basic skills, and compositional skills. This allows the LLM to process them in two steps. Just like humans learn new things by building on what they already know, the LLM may do the same through its tiered training schedule. Labradorite 13B (based on Meta’s Llama-2-13B model) and Merlinite 7B (based on the Mistral 7B model) were trained using a synthetic dataset of 1.2 million instructions that IBM Research created using the LAB approach. Their aligned models outperformed state-of-the-art chatbots on several tests, including those measuring natural language understanding and conversational fluency.
The approved instructions are then divided into three sections: knowledge, basic skills, and compositional skills. This allows the LLM to process them in two steps. Just like humans learn new things by building on what they already know, the LLM may do the same through its tiered training schedule. Labradorite 13B (based on Meta’s Llama-2-13B model) and Merlinite 7B (based on the Mistral 7B model) were trained using a synthetic dataset of 1.2 million instructions that IBM Research created using the LAB approach. Their aligned models outperformed state-of-the-art chatbots on several tests, including those measuring natural language understanding and conversational fluency.
Chatbots educated on massive amounts of synthetic data, such as Microsoft’s Orca-2 chatbot—trained on fifteen million instructions created by the GPT-4 model—lacked the performance of IBM’s Labradorite and Merlinite models. These outcomes can be better understood because of two characteristics of LAB. A considerably wider range of target tasks is produced by the teacher model, which generates synthetic examples from every taxonomy leaf node. Alternative approaches rely on random sampling, severely restricting the data’s breadth.
[To share your insights with us as part of editorial or sponsored content, please write to sghosh@martechseries.com]
Comments are closed.